

” or “Access denied”")


 Learning Guide")




 in SharePoint Online Modern Pages")





Introduction
In this article we will talk about Event-Driven Architectures. We choose to use the Azure Cloud Infrastructure.
Service Bus provides reliable, secure asynchronous messaging at scale. This article is written by the engineering team at CreateIT and it is intended to show you a case study in one of our projects for a client.
We’ll take a deeper dive into the Service Bus technology, architecture, and design choices. The post will cover both conceptual material as well as implementation details. Most importantly, we will discuss design and implementation of some of the features that provide secure and reliable messaging at scale, while minimizing operational cost.
Service Bus Entities
When we are working with Azure Service Bus, we can choose two Entities: Topics or Queues. You can have multiple Topics or Queues per Service Bus Namespace, but firstly you need to differ one from another. If you want a FIFO queue and only have one Consumer, then Queues are the way to go. If you need multiple Consumers, then the Topic is the better option. In this specific case we will create a Subscription per Consumer (Topics are only available from the Standard Pricing Tier).
Event-driven architectures
Benefits with event-driven architectures
What are the benefits of using a queue in the middle of these systems?
- We can decide to load balance the input from Customer Services. Let’s say there are a lot of updates being made to a customer, meaning a lot of events being published. We scale the number of consumers and user the competing pattern
- We can throttle the input. If on black Friday there are a ton of events and in case our Audit Log system is down. We simply store these events on the queue and consume them when the service is back online again. Of course we’d need to implement some logic for this behavior, but adding this “middleware” buys us options.
In our use case, we wanted to move to an implementation where the Web API doesn’t get affected by any changes on these external systems. But in order to change the implementation, we must first figure out what are the challenges associated with this change.
Challenges with event-driven architectures
Message/Event order
Azure Service Bus has a feature called sessions. A session provides a context to send and retrieve messages that will preserve ordered delivery. However, in our use case we chose not to use it.
Message Lock Duration
When we are using Queues, every message has a lock Duration. During this time the consumer needs to process it. But if this consumer needs to contact multiple external systems this time may rise and our messages could stop in the Dead-Letter. So the best practice is to change it accordingly to your needs. We recommend you to set this time extremely high in the beginning, and then do some tests to calculate the average.
After that add 30% more of its value, in case of some lengthy requests (in this case if we have outliers, they might stop in the Queue). If you are using a Topic, you will have a Lock Duration per Subscription. So make sure to adjust this time accordingly to its functions.
Implementation
In the Figure 1 you can see the initial architecture for the Customer Management system. It was responsible to make the requests to the other systems.
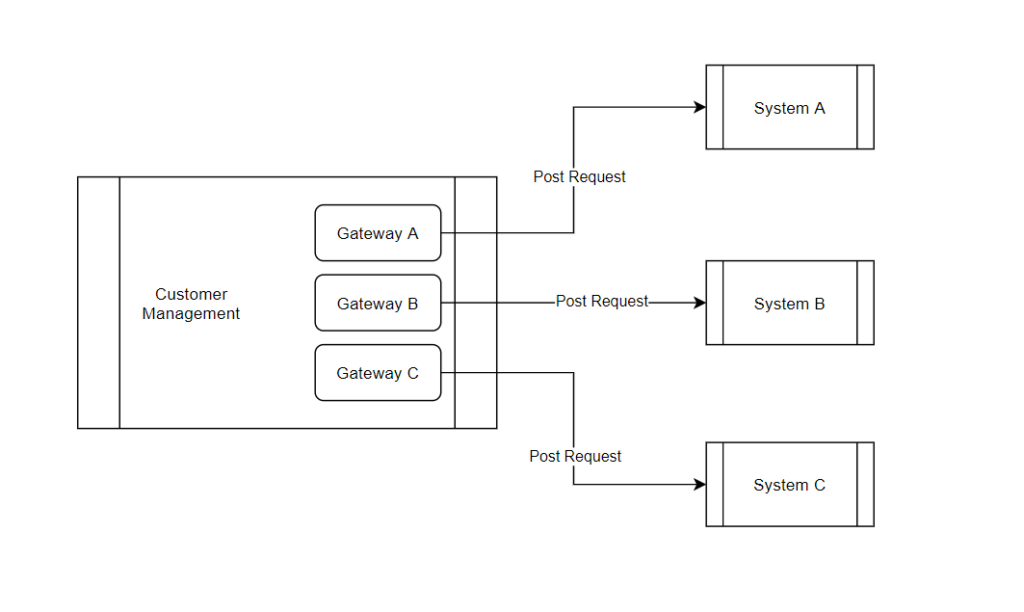
With the new implementation, a message broker was introduced and we used the event-carried state transfer pattern, meaning our events had all the information the consumer needed in order to do their job. We took in consideration the event notifications pattern, where the consumer would have to make a request to the API that originated the event, in order to get more information. But this brings new problems to the table. What if when the consumer code runs, the information for that customer ID changed? What if the event was CUSTOMER_CREATED but in the meanwhile the customer was deleted?
Retries with Polly
In a distributed system, many things can go wrong. The network can fail or have additional latency, systems may be temporarily down, etc. We use the Azure.ServiceBus.Messaging NuGet package so we are able to check if the exception is a transient fault or not (more information on these docs), then use Polly to setup retry logic and fallbacks. There are other options to implement retry policies, for example we took in consideration the Retry guidance for Azure Services documentation from Microsoft. Since we use the latest Azure SDK, the appropriate class would be ServiceBusRetryPolicy.
We configured Polly to retry to publish a message three times (this configuration is on appsettings.json), with exponential times between each attempt.
If after the third retry we can’t publish the message we need to save it, because it has crucial information. So to solve this issue we created a Fallback Gateway, to write these messages to a Container inside an Azure Storage Account.
Filters for message routing
This section only applies for Topics Entities on the Azure Service Bus.
We can add Filters on our Subscriptions to help us with routing each message to its specific Consumer. We considered two filter types:
- SQL Filter
- Correlation Filter
Using the Correlation Filter you can configure Custom Properties and create Filters for your needs. You just need to make sure the producer of the messages, includes the header, that you are currently using to filter, on the message.
With SQL Filters you can create conditional expression to evaluate the current message. Just make sure that all the system properties are prefixed with sys. in the expression. Either way, both filters work just choose one that suits you the most!
Dead-Letter Queue
In case the consumer application can’t process the message after the Max Delivery Count attempts, instead of returning it to the queue it will be sent automatically to the Dead-Letter queue. If you are using the Topic, each subscriber has its own Dead-Letter queue. You can also, configure different Max Delivery Counts Values for each Subscriber.
All messages that are published to the Service Bus have a TTL (Time-To-Live). After this time ends the message will be transferred automatically to the Dead-Letter. So make sure you adjust this time accordingly to your needs.
With this we are able to save messages that weren’t processed by the consumer application, but we should always strive to have an empty dead-letter queue.
Conclusion
Our first steps into an Event-Driven Architecture was a truly success!
We were able to expand our previous solution to be compatible with multiple external systems and instead of having the API sending a HTTPS request for each one we had this Application sending one message to a Topic in the Service Bus.
One of our goals was to have load balance in the Publisher Application. We went from a 1->3 dependency to a 1-> 1, as you can see in the Figure 2.
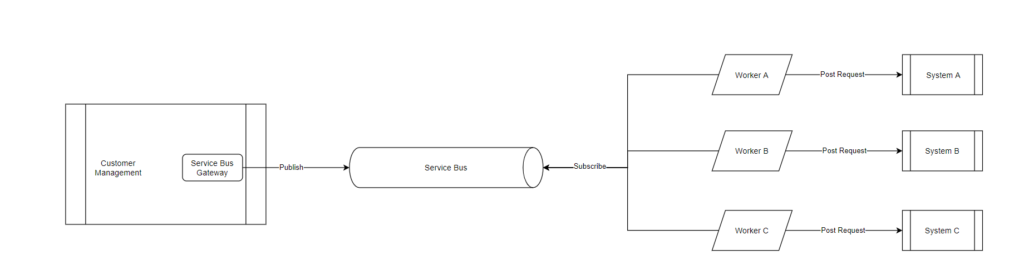
Which is great and keeps the system scalable and future proof. Our solution became more decoupled in order to keep the Application agnostic to these changes.
If you have a similar situation with an Event-Driven Architecture then we totally recommend you to check more about this technology and it’s features.
We would like to share a link to Microsoft Azure Service Bus GitHub. Most of the implementations of either the publisher or the subscriber were inspired by this documentation, so make sure you check it out!
If you have any questions, please write them down below.
Additional Links
Service Bus Exceptions
Service Bus Basic Steps
Tutorial with DotNet





")